

For a long time, migrating your batch pipelines to streaming meant being prepared to deal with a mix of JVM languages and high-maintenance distributed frameworks, as well as learning way more than you should about the internals of streaming systems. While this might fit teams with big human and time budgets, it made streaming harder to adopt for the rest of us.
How is the Modern Data Stack changing this?
Taking the leap from batch to streaming will never not be challenging, but it can sure enough be less painful. As the Modern Data Stack (MDS) reshapes the future of data engineering and analytics, there are some tools focusing on lowering the entry barrier to the space by providing:
1) Easier access to fresher data, faster;
2) Familiar interfaces that blend into your usual stack;
3) Minimal operational overhead.
At the same time, “not being fast enough” is still a common bottleneck in analytics, all the way from data transformation to visualization. One tool looking to change this is Materialize, a database purpose-built for streaming analytics and the MDS.
Streaming analytics in practice
Let’s use this demo to break down the fundamental steps involved in building an end-to-end analytics pipeline using Materialize and Metabase:
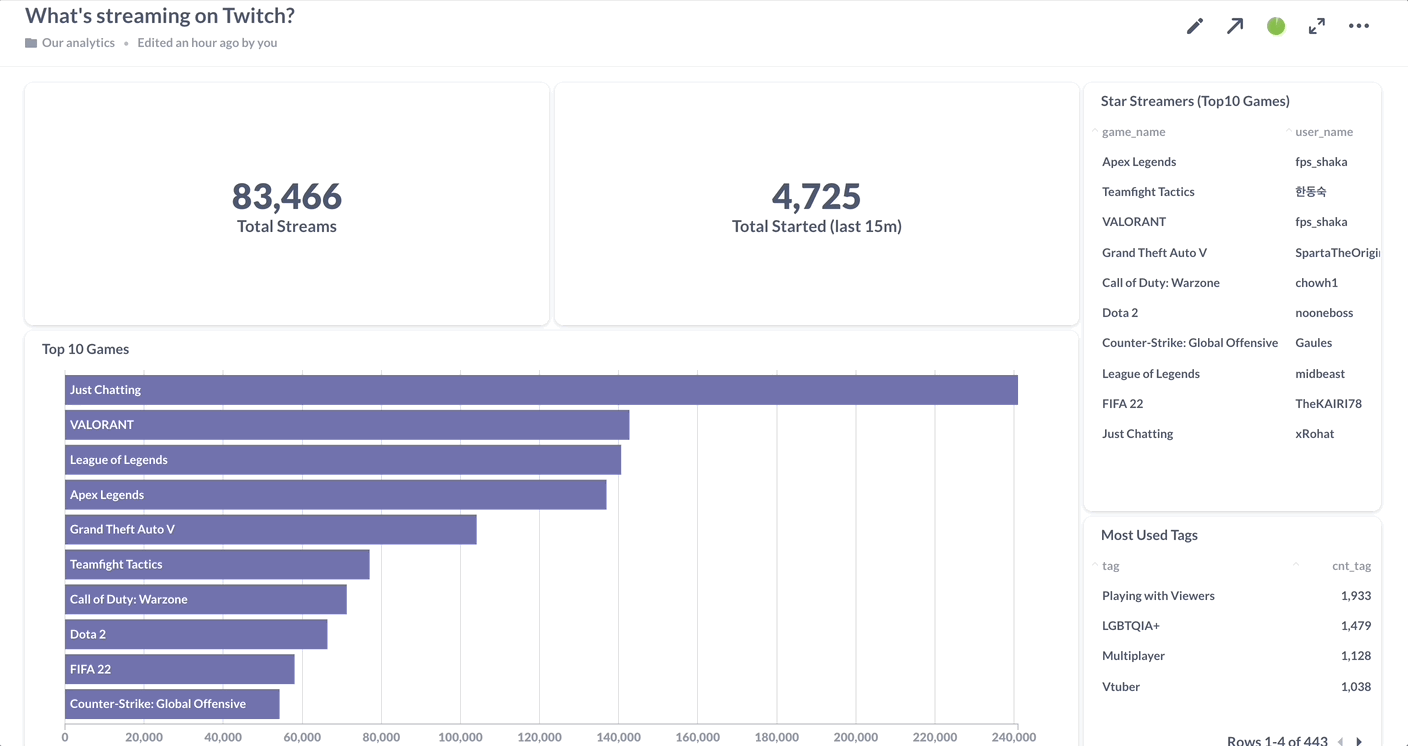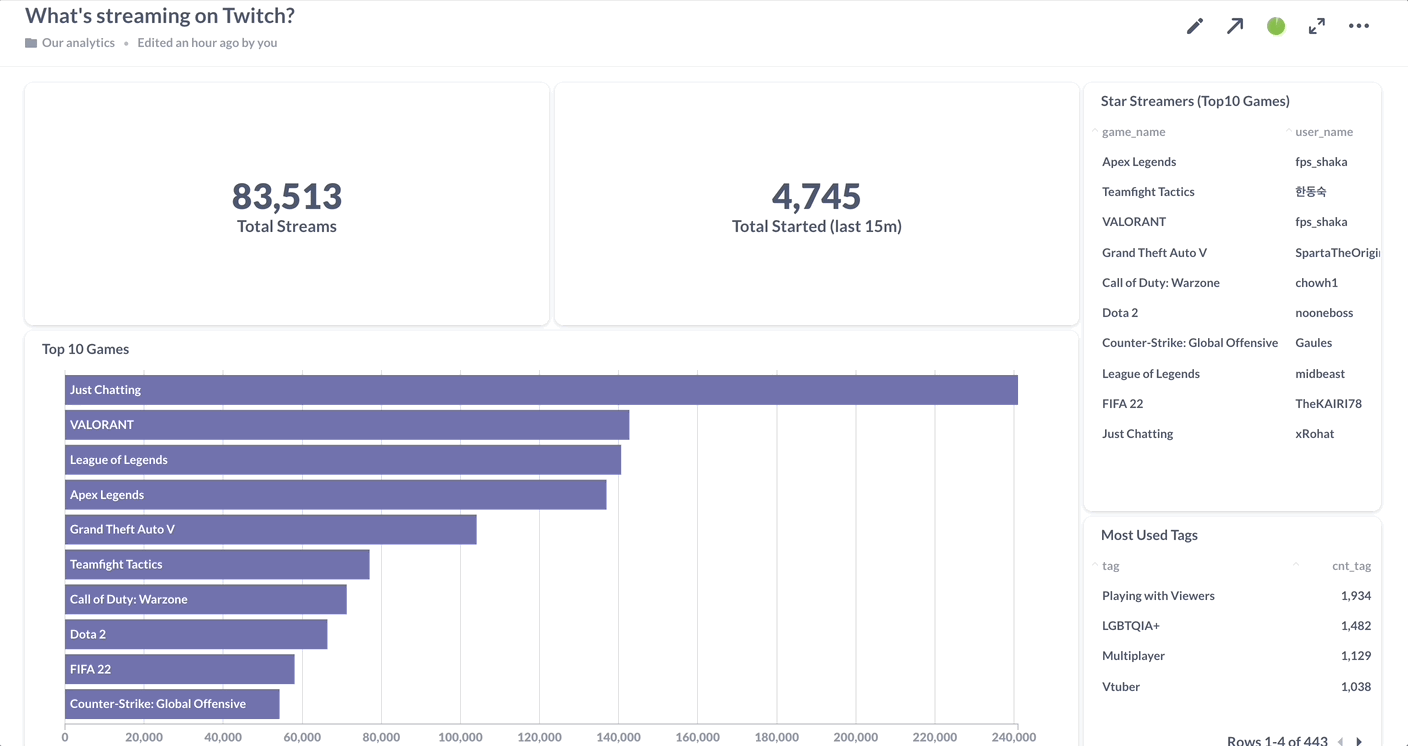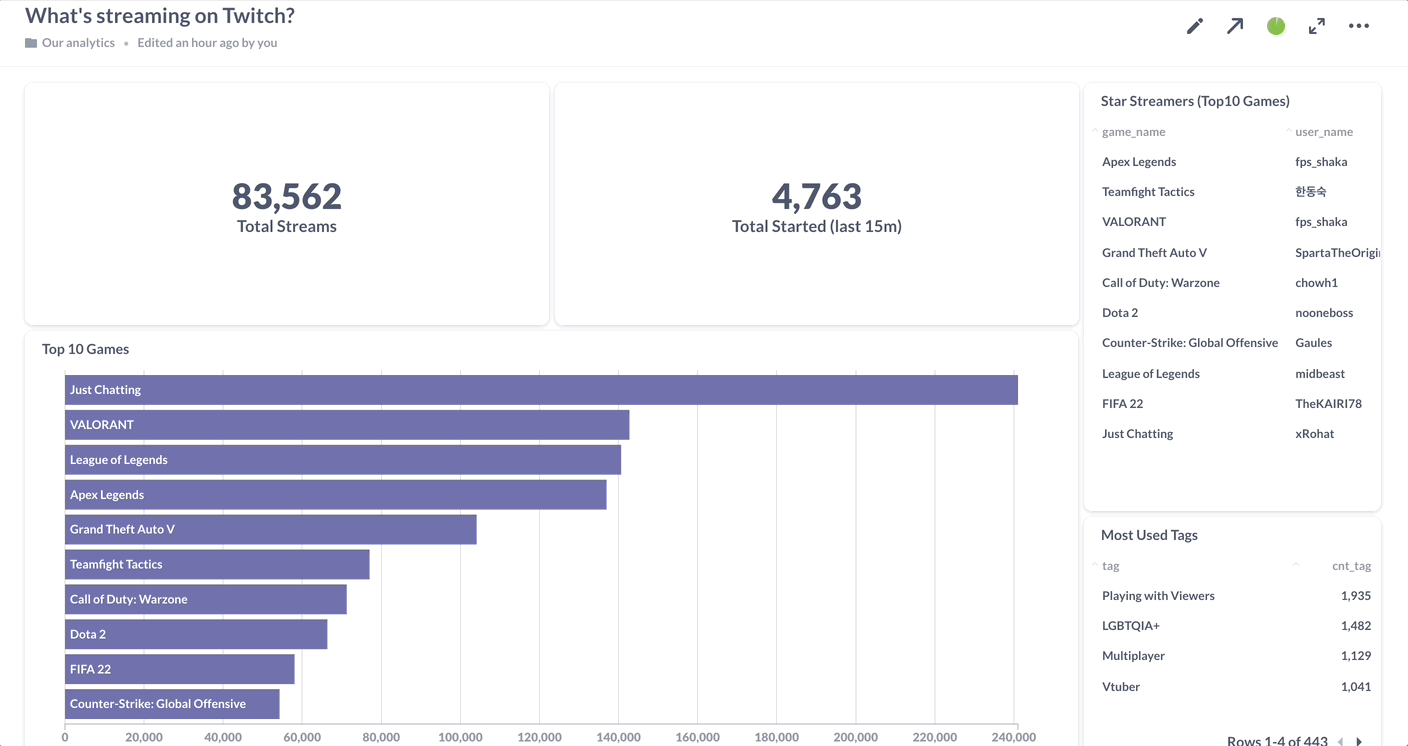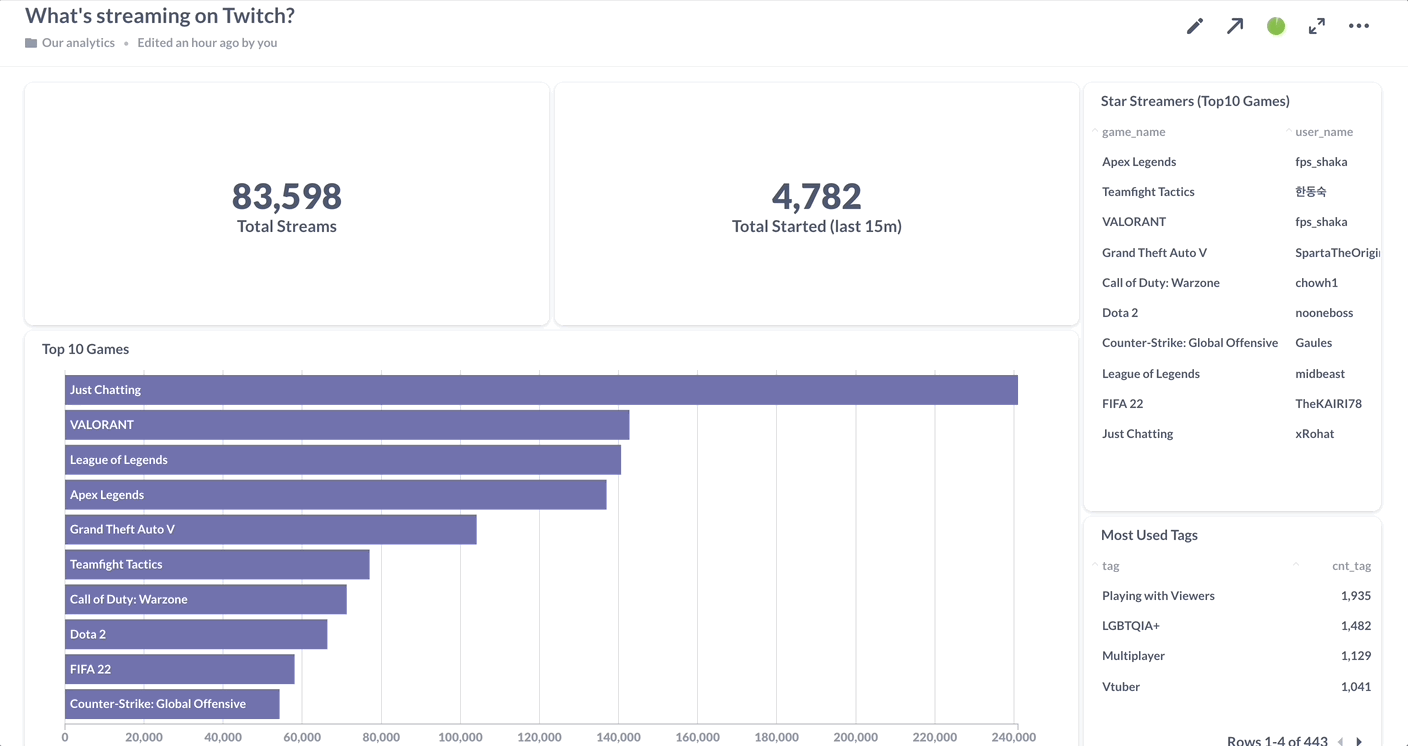
1. Connecting to a streaming data source
The first step is to let Materialize know where your data is located and what it looks like. In this demo, we’re using Kafka as a source, but you could also get started with a relational database like PostgreSQL, and push the replication stream to Materialize (aka change data capture).
2. Modeling data transformations using SQL
Next, you need to define your transformations as SQL queries (you can even use dbt!). These can be arbitrarily complex and use e.g. subqueries and n-way joins, because here’s the trick: instead of re-reading the source data and recomputing everything from scratch, Materialize will keep the results of your queries indexed in memory and incrementally update them as new source data streams in.
3. Visualizing the results
To finish it off, you can keep track of these results using Materialize’s native integration with Metabase. All queries are simply reading data out of self-updating materialized views, so you can set dashboards to auto-refresh every second without making the serving layer break a sweat, and rest assured that you’re delivering nothing but fresh, consistent insights to your end users.
Useful resources:
Demo
Blogpost: Hey, Materialize: what’s streaming on Twitch?
Materialize Docs