




In a data-driven world, clean data is essential for making smart decisions. But, working with dirty data is a common challenge—it can lead to poor analyses and bad decisions. In this article, we’ll walk through three ways to clean dirty data, turning your dirty dataset into something you can trust.
How to clean data
Let’s explore different methods for processing dirty data into clean data, from using tools in Metabase to setting up a full data pipeline or even using AI.
Clean data with models in Metabase
A simple way to clean your data in Metabase is by using models. These are key elements in Metabase that let you define and clean your data based on certain criteria.
Models can be built in SQL or using the query builder, allowing you to clean and structure your data directly in Metabase. They’re great for small to medium-sized datasets, especially if you need a quick solution.
Why use models in Metabase?
One of the best ways to implement data cleaning procedures in Metabase is to develop a model that represents the data based on particular criteria. Models are a fundamental building block in Metabase. They can be compared to derived tables or specialized saved questions, serving as the starting point for new analyses. Models can be built on SQL or query builder questions, allowing for the inclusion of customized and computed columns.
- Easy to use: No need for advanced technical skills to clean your data directly in the platform.
- Empower your team: Business teams can clean and adjust data without always relying on the data team.
Downside
- Not for huge datasets: Models can struggle with more complex or large datasets.
Example
Let’s consider a sample dataset of sales transactions for an online store. The raw data might look like this:
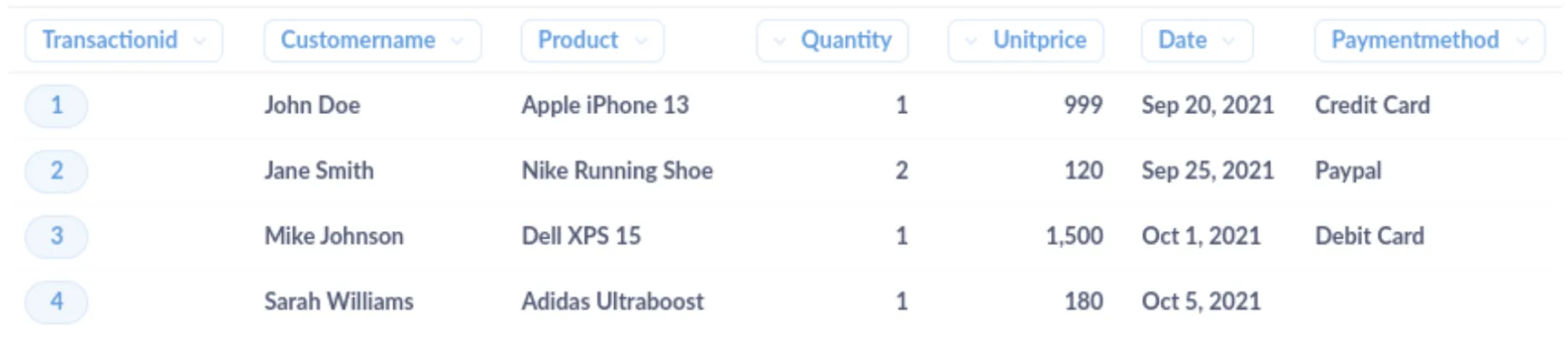
In this dataset, there are several issues that need to be addressed. To address them, you can implement patterns or functions in Metabase:
-
Inconsistent product names: Use regexextract to standardize product names by removing brand names and keeping only the product model. Example pattern:
REGEXEXTRACT([Product], '^(?:Apple|Nike|Dell|Adidas) (.*)$') -
Missing payment method information: Implement a function that checks for missing payment method values and replaces them with a default value or a placeholder. Example function:
COALESCE([PaymentMethod], 'Not Provided')
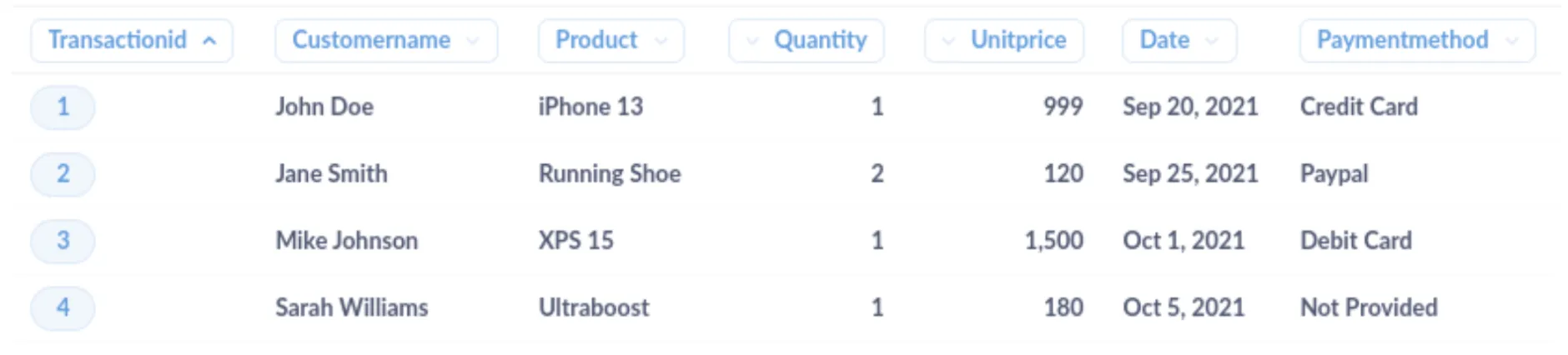
The cleaned dataset should look like this:
Clean data in your transformation pipeline
If you’re working with large or complex datasets, a data transformation pipeline can help. This process allows you to clean your data ahead of time, so it’s ready for analysis without extra work later.
By writing SQL queries to automate this process, you can ensure your data is clean before it even enters your analytics platform.
Want to learn more?: ETLs, ELTs, and Reverse ETLs
Why use a data transformation pipeline?
- Scalable: Works well with large, complex datasets.
- Time-saving: Automates the cleaning process, cutting down on manual work.
Fixes root issues: It cleans the data at its source, so you don’t just apply quick fixes.
Downside:
Needs technical skills: Building and maintaining a pipeline can require more expertise and resources.
Example of a transformation pipeline
Here is a sample dataset of customer orders.
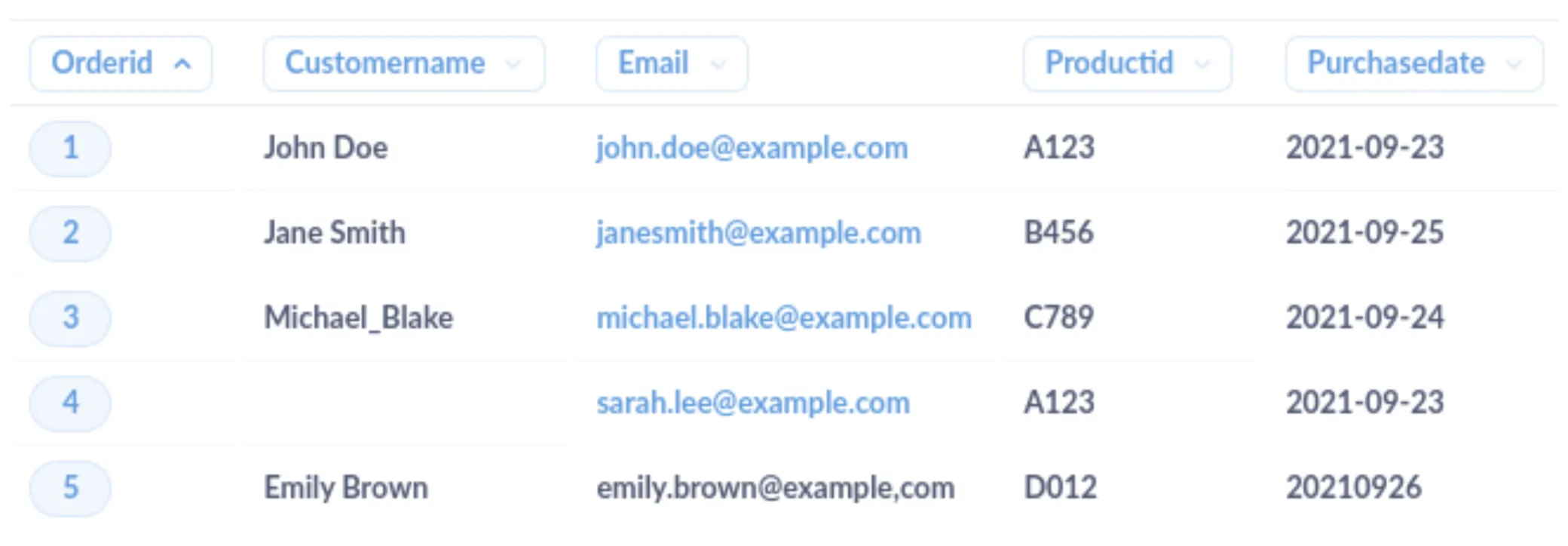
In this example, there are several issues that need to be cleaned up:
-
Inconsistent formatting in the
CustomerNamefield (e.g., underscores instead of spaces) -
Missing data in the
CustomerNamefield (NULL value) -
Incorrect delimiter in the
Emailfield for row 5 (comma instead of period) -
Inconsistent date format in the
PurchaseDatefield for row 5
You can use SQL to clean the data. Here’s an example of how to do this:
-- Create a temporary table with cleaned data
CREATE TEMPORARY TABLE cleaned_orders AS
SELECT
OrderID,
-- Replace underscores with spaces and handle NULL values in the CustomerName field
COALESCE(NULLIF(REPLACE(CustomerName, '_', ' '), ''), 'Unknown') AS CleanedCustomerName,
-- Replace comma with period in the Email field
REPLACE(Email, ',', '.') AS CleanedEmail,
ProductID,
-- Standardize the date format in the PurchaseDate field
STR_TO_DATE(PurchaseDate, '%Y-%m-%d') AS CleanedPurchaseDate
FROM
raw_orders;
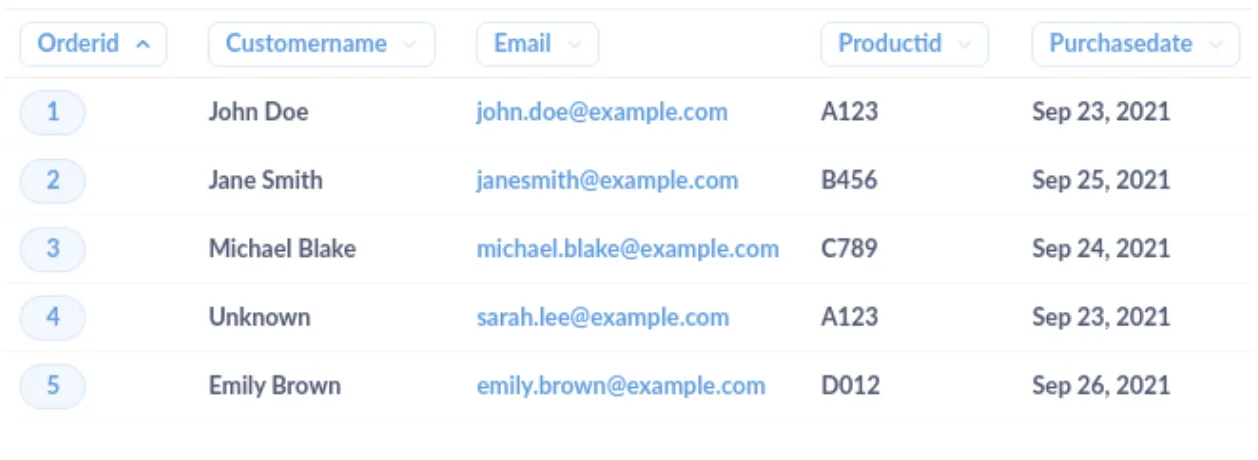
The cleaned dataset would look like this:
Use AI to clean your data
AI is transforming the way we approach data cleaning. Advanced algorithms and machine learning techniques, in particular Large Language Models such as OpenAI’s ChatGPT models, can automate the data cleaning processes.
Why use AI for data cleaning?
- Automation: AI automates the cleaning process, reducing human error.
- Handles large datasets: Scales quickly as your data grows.
- Improves over time: AI gets better at cleaning the data as it processes more information.
Downside:
- Initial investment: Setting up AI-driven solutions may require a bit more upfront work.
- Still need human oversight: While AI can clean a lot, having a person review the results is often necessary.
Example of using AI
A more complex example of data cleaning that AI can perform is identifying and resolving inconsistencies in clothing product attributes across multiple data sources. This often involves understanding the context, semantics, and relationships between different attributes such as color, size, and style.
Sample dataset:

In this sample dataset, the product attributes from three different data sources are inconsistent and need to be standardized for an online clothing store. Traditional cleaning may struggle to identify and resolve these inconsistencies effectively due to varying terminology, order, and structure of the attributes.
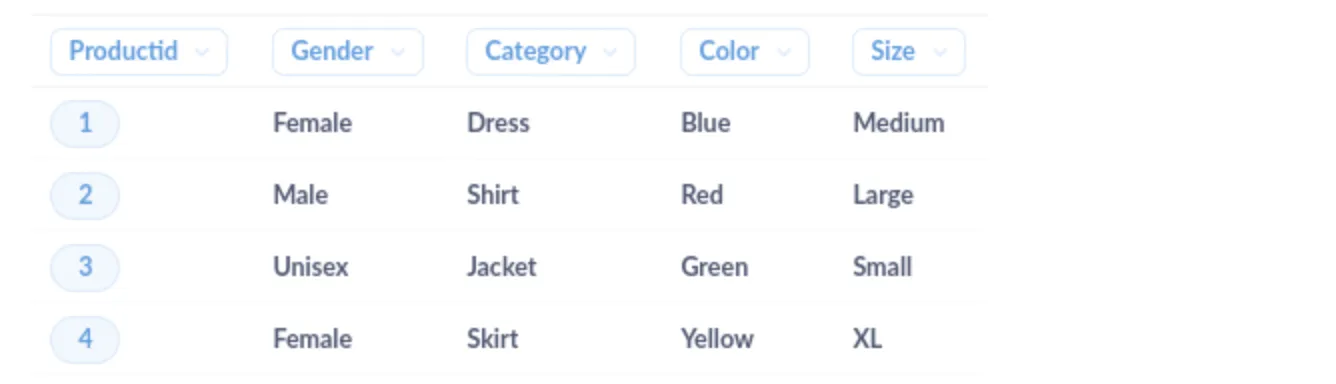
However, an AI-powered solution can analyze the context, semantics, and relationships between the different attributes and map them to a standardized set of attributes. For example, AI could recognize that “Women’s Dress, Blue, Size M”, “Female, Dress, M, Blu”, and “Dress, Medium, Woman, Color: Blue” all refer to the same product attributes and map them to a single, standardized format such as “Gender: Female, Category: Dress, Color: Blue, Size: Medium”.
The cleaned dataset would look like this:

Now we can split out the product attributes into separate columns for even easier analysis.
Which approach should you take?
The best data cleaning method for your business depends on various factors such as the type and quality of data, dataset size and complexity, available resources, and specific business goals. It is crucial to test and assess different cleaning methods before selecting one to integrate into your tech stack. Often, companies utilize a mix of the methods mentioned above. Check if the data sources are compatible with your preferred method and ensure that you have the necessary resources to execute the chosen solution effectively.