What is a schema?
A schema is the design or structure that defines the organization of a dataset: which columns are grouped into tables, how those tables relate to each other, and the rules and data types that define those columns.
Schema is an overloaded term; it’s an abstract word that has accumulated a lot of different definitions, and as a result can be confusing to sort out. Depending on the context, schema can mean:
- The overall structure, specification, or “blueprints” of your database
- A diagram that demonstrates how tables in your database relate to each other
- A single collection of tables (among many) within your database
Finally, schema sometimes means something specific to whichever database platform you’re using, like in Oracle, where schema refers to all objects in a database created by the same user.
Schema as overall structure: design and implementation
Once you’ve figured how your data fits together from a high-level standpoint (that is, your conceptual data model), the next step is creating a schema that reflects that data model, bringing it from the abstract to a database that your organization can use and populate with information.
Broadly speaking, this process is made up of two major steps:
- Design: map out the structure of your database, creating an entity relationship diagram (ERD) in the process.
- Implementation: Use that ERD to generate the SQL commands that, when run in your database, will create your desired schema.
What your schema design process looks like depends on whether you’re dealing with transactional or analytical databases, and whether you’re starting from scratch or have already begun collecting data. Regardless of at which point you’re designing schemas, you’ll have to think deeply about the needs of your organization and what questions you anticipate asking of your data.
Schema-on-write vs. schema-on-read
Most traditional relational databases use a schema-on-write system, where data gets verified and formatted into a schema before it’s written to that database. Since the data being written must conform to whatever specific data integrity rules you’ve established (like requiring that all values in a field be unique, not accepting null values in a field, or formatting dates a certain way), adding this new data to your database can be slow. However, the read times are fast, since that data has already been verified.
In a schema-on-read system, data (like in a data lake) is only verified once it’s been read, or pulled from that database. Schema-on-read systems tend to be more flexible, as you can store unstructured data without worrying about it conforming to a rigid data model. In this case, writing data is faster (since that data doesn’t need to be verified as it gets loaded in), but queries take more time to execute.
Whether you opt for a schema-on-write or schema-on-read strategy will depend on your organization’s needs and specific use cases. If having meticulously structured and consistent datasets is important to your organization, a schema-on-write system may be your best bet. By contrast, if you regularly need to pull in a wide variety of data without always knowing exactly what it that data looks like, you may want to use a schema-on-write system.
Logical and physical schemas
Regardless of whether you’re working with a schema-on-write or schema-on-read system, you’ll also need to think about database structure and its implementation — that is, your logical and physical schemas. Logical schemas define the structure of your data, while the actual implementation of that structure (like how and where you store the files and code that make up your database) belongs to a physical schema.
Logical schemas
Logical schemas are created by diagramming how tables and their fields relate to each other. In creating a logical schema, you’ll establish tables, relationships, fields, and views, answering questions like:
- What data are we collecting, or do we want to collect?
- What tables does your database (or individual schema within it) need?
- How do those tables relate to each other?
- What fields does does each table need?
- What are the data types for each of those fields?
- Which fields are required?
Schema as diagram: mapping out entities and relationships
In answering these and other questions, you’ll likely sketch out an entity relationship diagram (ERD) that defines each table, its fields, their integrity constraints, and the relationships between those tables, including the primary and foreign keys that establish those connections and whether those relationships between tables are one-to-one, one-to-many, or many-to-one. Visualizing your tables and how they relate to each other can also bring to light any major omissions or conflicts. And yes, sometimes you’ll see these diagrams themselves referred to as schemas.
The image below shows an entity relationship diagram of a schema with two tables, PRODUCTS and MANUFACTURER. The “(PK)” and “(FK)” notations tell us which fields are primary and foreign keys, and the line linking these tables indicates a one-to-many relationship, in that one manufacturer can be linked to many products.
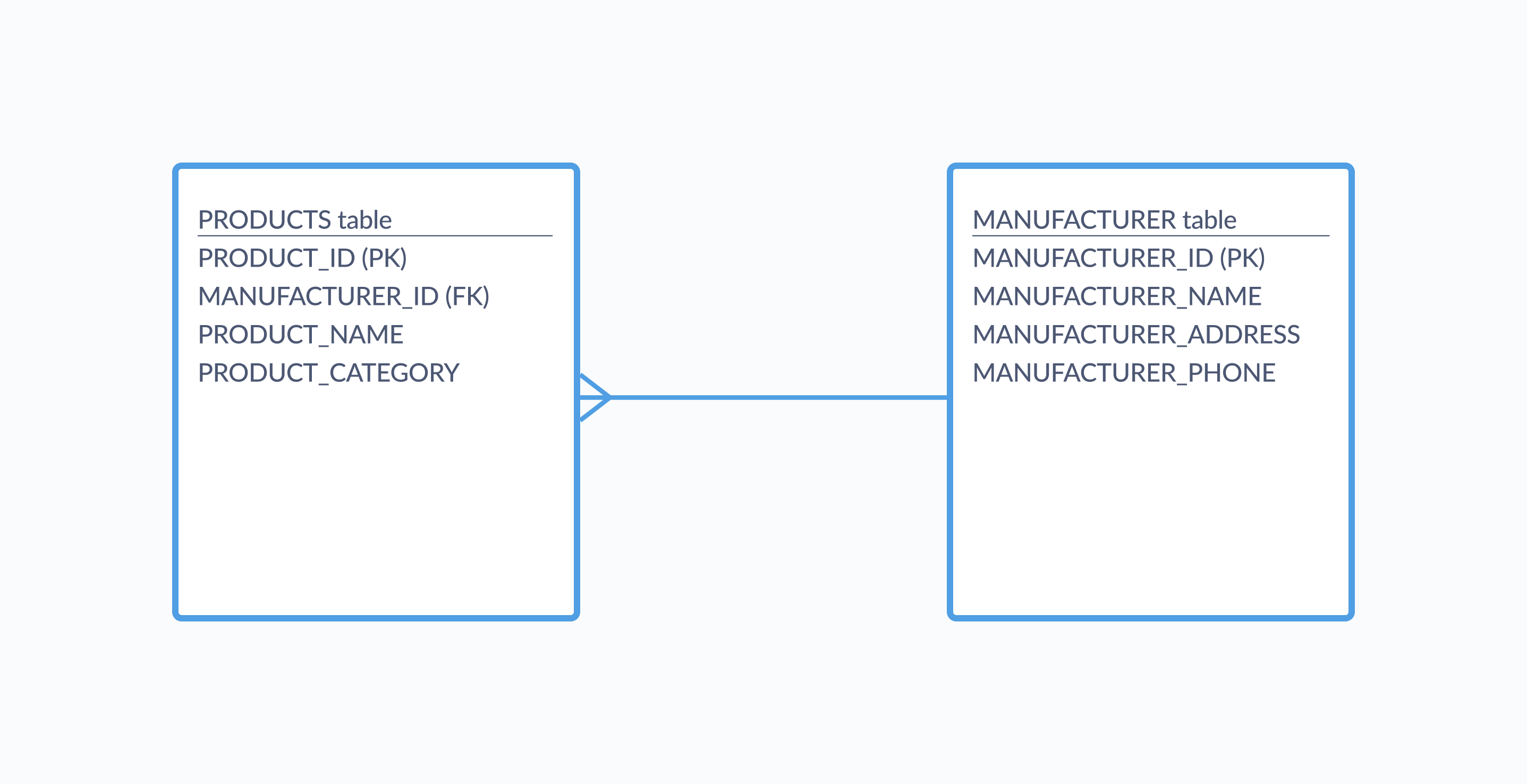
You can map out your schema on paper or using design software that can directly translate your diagram to the SQL commands that you’ll need to implement your database. At this point your schema is platform-agnostic; mapping out those rules and relationships doesn’t tie you to any single database software.
Physical schemas
Once you’ve identified the logical configuration of your database, you’ll create a physical schema to implement it into a specific RDBMS, defining where your database files will live as well as their storage allocation on a disk.
Schema as one collection of tables among many
While a single collection of tables may be sufficient if your database only sees a few users and contains data that everyone needs to access, you may find that a relying on a single schema in your database doesn’t cut it for your organization. If you’re handling data across a lot of tables (think in the dozens, hundreds, or thousands), grouping those tables into separate schemas will help from an organizational standpoint, making it so you can store similar information together while retaining the ability to query across schemas when necessary.
Keeping multiple schemas within a database can be helpful from a security standpoint as well, like separating tables that hold sensitive information into a schema that only those who need to can access, usually in combination with views.
Schema design for transactional vs. analytical databases
When thinking about schemas for transactional databases (also known as operational databases), your data will need to be normalized to some extent and adhere to data integrity standards, since efficiency and performance for those small transactions and OLTP are crucial.
Designing a schema for an analytical databases will look different. For starters, you’ve probably already collected raw data, possibly from multiple sources, and now need to impose some structure in order to analyze it. In this case, redundancy is okay, as analytical databases place greater emphasis on explorability and less on performance. Here your schema can also be more loosely defined, as no fixed patterns (like normalization) are needed. Schema design for analytical databases is more about understanding where data from your various sources lives, and knowing what tables you’ll need to join to answers questions you have.
Star schema
One common structure you’ll see applied to analytical databases is a star schema, which separates data into fact tables (that is, quantitative data) that relate to multiple dimension tables describing those facts. In a simple implementation of a star schema, several dimension tables all surround and relate to a single fact table, looking like a star in diagram form with the fact table at its center, like so:
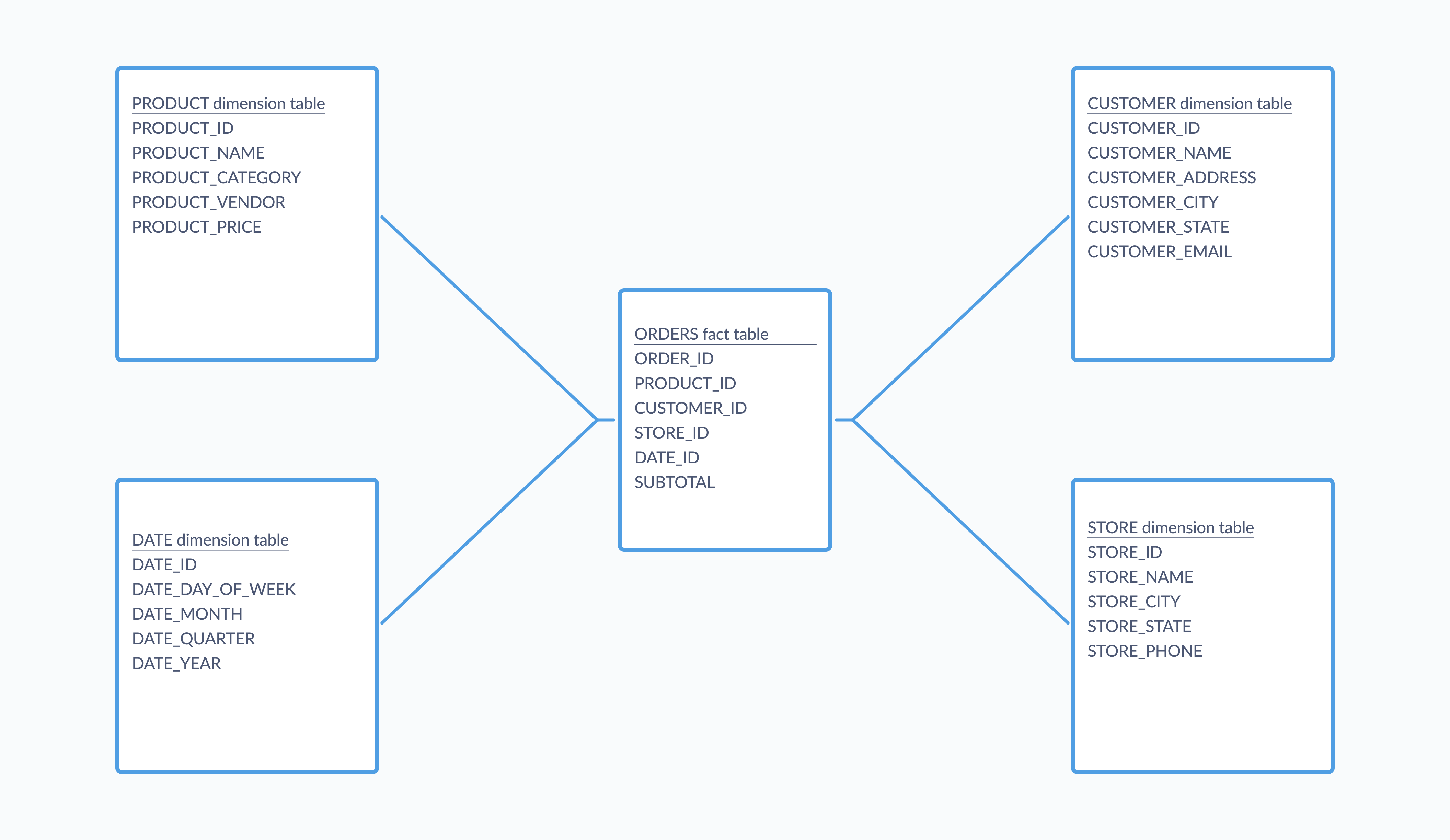
Tables within a star schema are typically denormalized, which leads to better performance for analytical queries.
Creating a database schema
Most database platforms (such as Redshift and PostgreSQL) use “schema” to mean the configuration of a dataset and non-nested groupings of tables and other named objects within that dataset, though Oracle defines schema as all of the objects created by and belonging to a single database user.
To create a schema within your RDBMS, use the query CREATE SCHEMA, like in this example, where we create a schema with two tables that are linked by the customer_id field:
CREATE SCHEMA new_schema;
CREATE TABLE new_schema.orders (
order_id
product_id
customer_id
subtotal
order_date
)
CREATE TABLE new_schema.customers (
customer_id
customer_name
customer_address
customer_email
);
This is a very simple schema; we didn’t specify data types or any other constraints on the fields in our tables. If we wanted to require the customer_id field in the customers table and indicate that its data type is an integer, we’d format that field like this:
customer_id INT NOT NULL
Note that in MySQL, CREATE SCHEMA is synonymous with CREATE DATABASE.
Related terms
Further reading
- Common data model mistakes made by startups
- A short overview of databases
- Data types and metadata
- Database table relationships