‧
13 min read
Improving the performance of the popular Clojure development tool clojure-lsp
Sashko Yakushev
‧ 13 min read

Share this article
Development tools can sometimes struggle when dealing with large codebases. This gives performance nerds like me a reason to investigate. In this case, I ended up cutting clojure-lsp’s startup time in half and memory allocation by two thirds.
Part 1: The mystery of heap headroom
Devs working on Metabase were complaining about LSP taking too long to boot, so I wondered how long it could be. A few seconds? Half a minute? Imagine my surprise when I saw this:
(time (clojure-lsp.api/analyze-project-only!
{:project-root (clojure.java.io/file "/path/to/metabase")}))
"Elapsed time: 178981.918417 msecs"
Three minutes is a long time.
The first suspect was heap size. There is a good rule of a thumb: if some process in Clojure (or any JDK language) takes longer to complete than anticipated, or doesn’t finish at all, you should check the heap.
I used VisualVM to inspect our Clojure process and ran the benchmarking command, which gave us something like this:
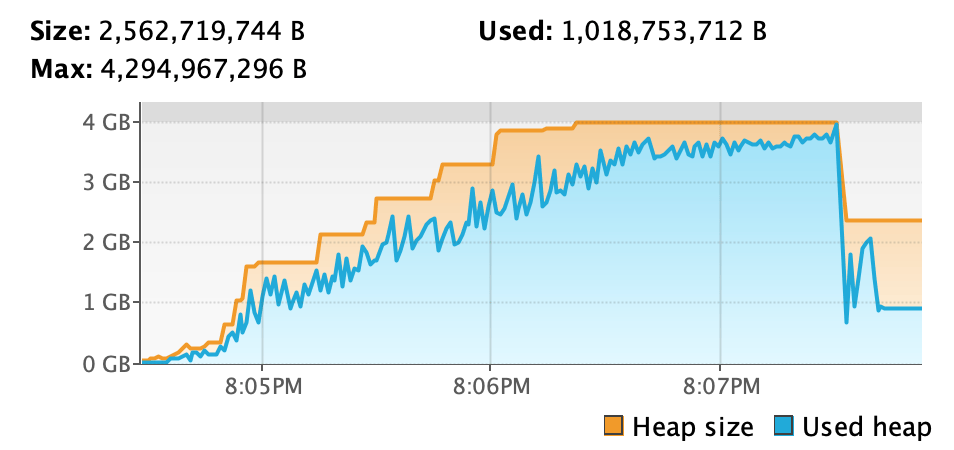
What’s going on here? My laptop has 16 GB of RAM. By default, Java will take 25% of total RAM as the maximum heap size for the process. In my case, that means 4GB max heap, as you see in the screenshot. Clojure-lsp’s analysis fills up the heap with more and more unfreeable data, meaning objects that don’t get garbage-collected. The heap headroom (the amount of free heap space after garbage collection) becomes smaller and smaller, which means garbage collection has to run more often, to the point where a GC run has to start up before the last run can complete.
Giving more heap space to the process by adding an -J-Xmx6g argument to the REPL command line shows a different picture:
(time (clojure-lsp.api/analyze-project-only!
{:project-root (clojure.java.io/file "/path/to/metabase")}))
"Elapsed time: 115370.613041 msecs"
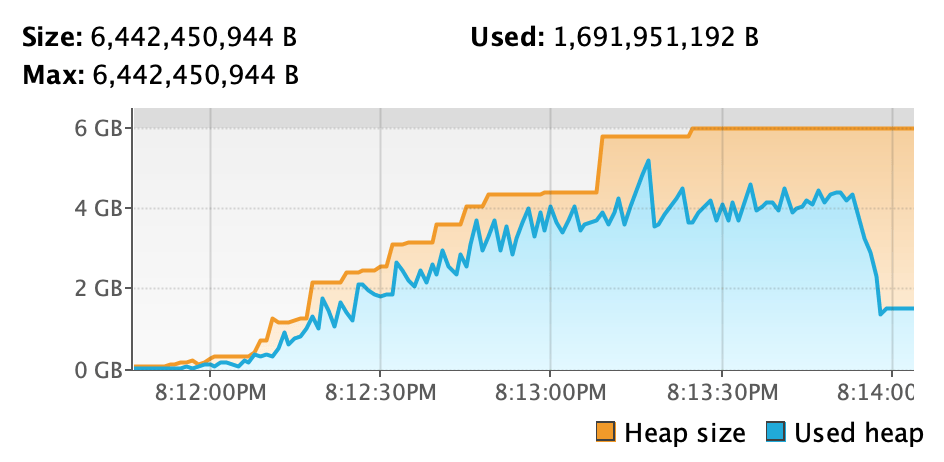
Still almost two minutes, but we’ve shaved off a minute by just giving the process more space to breathe. The heap plot shows that “used heap” no longer hugs the “max heap” threshold so tightly, so GCs trigger less often.
Part 2: Profiling and optimizations
My next step was to use clj-async-profiler to obtain a flamegraph of the benchmark above. I took an allocation profile instead of a regular CPU profile because I’ve found that optimizing allocation hotspots results in roughly the same execution time savings, but allocation profiles have less variance and skew.
(clj-async-profiler.core/profile {:event :alloc}
(clojure-lsp.api/analyze-project-only! {:project-root (clojure.java.io/file "/path/to/metabase")}))
A flamegraph is a good way to spot the hot code in stack traces (see this tutorial for more on flamegraphs). On the Y axis, you have stacks that grow from bottom to top. The position of the frame signifies which function calls which, and the height of the flamegraph shows the stack’s depth (which usually doesn’t matter).
On the X-axis, the width of a frame shows how much total time each function call takes (or, in this case, the number of allocations of a particular object class). The coordinate of the frame on the X-axis doesn’t imply its position in time; in fact, the X-axis coordinate doesn’t mean anything (just its width).
Looking at the flamegraph, most of clojure-lsp’s initialization is taken up by clj-kondo. If you search in the embedded graph for “kondo,” you’ll find that 95.41% of all frames match, meaning almost all work is kondo-related.
After massaging the flamegraph and pruning irrelevant pieces, I found several significant inefficiencies and solutions for them.
deep-merge
The deep-merge function is similar to clojure.core/merge, but when deep-merge merges maps, it also merges values with duplicate keys in those maps. There were a few things to be improved here:
- If the value in the resulting map doesn’t change, don’t perform the
assocoperation. So ifmalready has{:k1 someval}, we can skip(assoc m :k1 someval). - Before merging two sets, check if they’re equal. If they are, there’s no need to merge them; just return one of them.
- Only use Clojure transients for large collections, as transients bear some static upfront overhead, which can be less efficient than using simple vectors for small collections.
rewrite-clj improvements
rewrite-clj is a library that Kondo and LSP use to read and parse Clojure. I’ve applied several optimizations to it, but the most impactful change was dropping a dynamic variable on a hot path.
In Clojure, dynamic variables (usually *earmuffed*) allow for passing “hidden” context to other functions instead of adding explicit arguments. In a sense, this hidden context is global state, but restricted to stack scope. A simple example:
(def ^:dynamic *honorific* nil)
(defn hello [name]
(if *honorific*
(str *honorific* " " name)
name))
(hello "John")
=> "John"
(binding [*honorific* "Mrs."]
(hello "Smith"))
=> "Mrs. Smith"
Here, having *honorific* as a dynamic variable saved us the trouble of adding another argument to hello. But setting a value for a dynamic variable with binding involves creating a new hashmap every time, and assoc-ing the value to it. That means allocations and spent cycles. So, if you care about the performance of a particular hot function, make sure to pass all arguments explicitly.
Better memoization
Clojure kindly provides the clojure.core/memoize function, which caches the outputs of a function for the given inputs.memoize’s implementation, however, is quite simplistic and unoptimized:
- To accept functions of any arity,
clojure.core/memoizeuses a list of arguments as the cache key. Rolling arguments into the list triggers additional allocations. memoizealso usesfindto look up the value for the key in the cache. When the map contains the key,findreturns a key-value pair, a MapEntry object, which again needs to be allocated in the heap.
Because clj-kondo only needs memoization for one- and two-argument functions, a more specialized implementation was warranted. For a single argument, the code is straightforward. For two arguments, the main trick is to structure the cache as a nested map {arg1 {arg2 cached-value}} instead of {[arg1 arg2] cached-value}. Nesting the map avoids wrapping arguments into a vector during the lookup.
Part 3: Measuring total allocations
I proposed each optimization as a separate PR to clj-kondo, because I thought it would be helpful for the maintainer, the venerable Michiel Borkent, to see the impact of each optimization. The timing differences for each improvement separately were too flaky to observe a meaningful difference, so I came up with another metric: the total number of allocated bytes during the benchmark.
The following script does the work of hooking into GC events and captures how many bytes were freed each time. In the end, we add up all those bytes to calculate the total allocated value.
(import
'[com.sun.management GarbageCollectionNotificationInfo GcInfo]
'[javax.management NotificationEmitter]
'[java.lang.management ManagementFactory MemoryUsage]
'[javax.management NotificationListener]
'[javax.management.openmbean CompositeData])
(def memory-bean (ManagementFactory/getMemoryMXBean))
(def gc-collections (atom []))
(defn calc-freed
"Return the number of bytes reclaimed by a given GC run."
[^GcInfo gc-info]
(let [before (.getMemoryUsageBeforeGc gc-info)
after (.getMemoryUsageAfterGc gc-info)]
(reduce (fn [total pool]
(let [used-before (.getUsed ^MemoryUsage (get before pool))
used-after (.getUsed ^MemoryUsage (get after pool))]
(if (> used-before used-after)
(+ total (- used-before used-after))
total)))
0
(keys before))))
(defn install-gc-listener!
"Add a hook that runs on every GC invocation to intercept and remember how
much heap space the GC freed."
[]
(doseq [gc-bean (ManagementFactory/getGarbageCollectorMXBeans)]
(.addNotificationListener
^NotificationEmitter gc-bean
(reify NotificationListener
(handleNotification [_ notification _]
(when (= (.getType notification)
GarbageCollectionNotificationInfo/GARBAGE_COLLECTION_NOTIFICATION)
(let [info (GarbageCollectionNotificationInfo/from
^CompositeData (.getUserData notification))
gc-info (.getGcInfo info)
freed (calc-freed gc-info)]
(swap! gc-collections conj freed)))))
nil nil)))
(install-gc-listener!)
(def used-heap-before (.getUsed (.getHeapMemoryUsage memory-bean)))
(time (clojure-lsp.api/analyze-project-only! {:project-root (clojure.java.io/file "/path/to/metabase")}))
(defn print-allocation-stats []
(let [used-heap-after (.getUsed (.getHeapMemoryUsage memory-bean))
total-allocated (+ (reduce + @gc-collections)
used-heap-after
(- used-heap-before))]
(println (format "Allocation stats: %s GC collections, allocated %.1fGB"
(count @gc-collections)
(double (/ total-allocated 1e9))))))
(print-allocation-stats)
With this script, I got the following numbers before and after the applied optimizations:
;; Before
"Elapsed time: 89335.263292 msecs"
Allocation stats: 245 GC collections, allocated 145.0GB
;; After
"Elapsed time: 46784.39225 msecs"
Allocation stats: 117 GC collections, allocated 51.6GB
We see a 2x improvement in the elapsed time and almost 3x reduction of the number of bytes allocated on the heap.
To see where exactly the improvements manifested in the code, I took a second allocation profile using clj-async-profiler to generate a diffgraph.
A diffraph is a type of flamegraph that combines two profiles and shows differences between them. Color represents the direction and intensity of change. Blue frames mean that the second profile contains fewer samples for that code path (which means faster, fewer allocations, etc.). Red frames show more samples than before.
Highlighting the diffgraph’s base shows that we reduced allocations by ~66% (which matches the benchmark results above). If you scroll up to stacks of more saturated blue, you’ll see which parts of the code were the most affected. For instance, clj-kondo.impl.analyzer.namespace/analyze-ns-decl has almost completely disappeared from the profile (-96% allocations on that codepath), clj-kondo.impl.rewrite-clj.parser.core/parse-delim performs 93% fewer allocations than before, and so on. When you see a sea of blue on the diffgraph, you know you are doing something right.
Conclusions
Being able to do something in a development tool is the main part, but speed and ergonomics matter just as much. A tool that is “almost instant” when employed in a small project may become unwieldy in an industrial-scale one like the Metabase codebase.
We significantly improved clojure-lsp’s initialization time and memory pressure. Eric Dallo, the maintainer of clojure-lsp, has kindly provided his own benchmark results and analysis of the optimizations, and has independently confirmed the speed-ups on codebases comparable to Metabase. Our proposed changes are already merged, and will ship in the new release of clojure-lsp.
There is still plenty to be done to improve the clojure-lsp experience. The server still keeps a weighty amount of heap when loaded (around 2-3 GB) and there are probably a lot more opportunities to reduce this number. But that’s a story for another blog post.